목차
1. 개요
2. Data 설명
3. EDA
4. 결론
5. 참고 url
# 개요
https://www.kaggle.com/c/instacart-market-basket-analysis
Instacart Market Basket Analysis
Which products will an Instacart consumer purchase again?
www.kaggle.com
당신이 꼼꼼하게 계획된 식료품 리스트를 기반으로 쇼핑을 하든, 충독적으로 쇼핑하든, 우리의 음식구매패턴은 우리가 누구인지 정의한다. 식료품 주문 및 배달 앱인 Instacart는 필요할 때 냉장고와 선반안에 당신이 가장 좋아하는 것으로 쉽게 채울 수 있도록 하는 것을 목표로 한다. 인스타카트 앱을 통해 상품을 고른 후, 자신의 장바구니를 검토하고 구매한다.
Instacart의 데이터 분석팀은 이 즐거운 쇼핑 경험을 제공하는 데 큰 역할을 한다. 현재 그들은 사용자가 어떤 제품을 다시 구매할지 예측하거나, 처음 구매하거나, 다음에 장바구니에 추가할지를 예측하는 모델을 개발하기 위해 트랜잭션 데이터를 사용한다. 최근에, Instacart는 300만 개의 데이터를 오픈했다.
이 경쟁에서, Instacart는 kaggle 에서 어떤 제품이 사용자의 다음 구매에 포함될 것인지를 예측하기 위한 데이터분석 모델을 찾고 있다.
# Data 설명
| Data | Data Column |
|
|
# EDA
Step1 . 라이브러리 / DataSet 불러오기
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette()
%matplotlib inline
pd.options.mode.chained_assignment = None# matplotlib 한글 폰트 깨짐 방지
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name) order_products_train_df = pd.read_csv(r'파일저장 경로\order_products__train.csv')
order_products_prior_df = pd.read_csv(r'파일저장 경로\order_products__prior.csv')
orders_df = pd.read_csv(r'파일저장 경로\orders.csv')
products_df = pd.read_csv(r'파일저장 경로\products.csv')
aisles_df = pd.read_csv(r'파일저장 경로\aisles.csv')
departments_df = pd.read_csv(r'파일저장 경로\departments.csv')
Step 2 . EDA
- 각 그룹군 그래프로 나타내기
cnt_srs = orders_df.eval_set.value_counts()
plt.figure(figsize=(12,8))
sns.barplot(cnt_srs.index, cnt_srs.values, alpha=0.8, color=color[1])
plt.ylabel('총 갯수', fontsize=12)
plt.xlabel('고객 Type 군', fontsize=12)
plt.title('각 고객군의 수', fontsize=15)
plt.show()
def get_unique_count(x):
return len(np.unique(x))
cnt_srs = orders_df.groupby("eval_set")["user_id"].aggregate(get_unique_count)
cnt_srs
- 각 고객별로 가장 많이 주문한 개수를 그래프로 나타내기
cnt_srs = orders_df.groupby("user_id")["order_number"].aggregate(np.max).reset_index()
cnt_srs = cnt_srs.order_number.value_counts()
plt.figure(figsize=(12,8))
sns.barplot(cnt_srs.index, cnt_srs.values, alpha=0.8, color=color[2])
plt.ylabel('구매 발생 횟수', fontsize=12)
plt.xlabel('Maximum 구매 갯수', fontsize=12)
plt.xticks(rotation='vertical')
plt.show()

- 요일별 구매량 추이 확인
plt.figure(figsize=(20,15))
sns.countplot(x="order_dow", data=orders_df, color=color[0]) # order_dow 는 요일을 의미
plt.xlabel('요일', fontsize=12)
plt.ylabel('구매량', fontsize=12)
plt.xticks([2,3,4,5,6,0,1],['월','화','수','목','금','토','일'])
plt.title("요일별 구매량", fontsize=15)
plt.show()
- 각 시간대별로 구매개수 그래프로 나타내기
orders_dforder_id user_id eval_set order_number order_dow order_hour_of_day days_since_prior_order
| 0 | 2539329 | 1 | prior | 1 | 2 | 8 | NaN |
| 1 | 2398795 | 1 | prior | 2 | 3 | 7 | 15.0 |
| 2 | 473747 | 1 | prior | 3 | 3 | 12 | 21.0 |
| 3 | 2254736 | 1 | prior | 4 | 4 | 7 | 29.0 |
| 4 | 431534 | 1 | prior | 5 | 4 | 15 | 28.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3421078 | 2266710 | 206209 | prior | 10 | 5 | 18 | 29.0 |
| 3421079 | 1854736 | 206209 | prior | 11 | 4 | 10 | 30.0 |
| 3421080 | 626363 | 206209 | prior | 12 | 1 | 12 | 18.0 |
| 3421081 | 2977660 | 206209 | prior | 13 | 1 | 12 | 7.0 |
| 3421082 | 272231 | 206209 | train | 14 | 6 | 14 | 30.0 |
plt.figure(figsize=(12,8))
sns.countplot(x="order_hour_of_day", data=orders_df, color=color[1])
plt.ylabel('구매량', fontsize=12)
plt.xlabel('하루 중 시간', fontsize=12)
plt.title("하루 중 구매량", fontsize=15)
plt.show()
- 요일별/ 시간대별 구매 추이 확인
grouped_df = orders_df.groupby(['order_dow','order_hour_of_day'])['order_number'].aggregate('count').reset_index()
grouped_df = grouped_df.pivot('order_dow','order_hour_of_day','order_number')
plt.figure(figsize = (18,9))
sns.heatmap(grouped_df)
plt.title('요일별/시간별 구매량')
plt.yticks([2,3,4,5,6,0,1],['월','화','수','목','금','토','일'])
plt.show()

- prior 고객군 대상 분석
plt.figure(figsize=(12,8))
sns.countplot(x='days_since_prior_order', data= orders_df, color=color[3])
plt.ylabel('판매량',fontsize=12)
plt.xlabel('prior 주문 일수', fontsize = 12)
plt.xticks(rotation='vertical')
plt.title('prior 구매의 일별 빈도분포')
#판매량이 가장 높은 요일은 30일, 낮은 요일은 25일 이다. 1일~7일까지는 증가추세이고, 8일~29일까지는 감소추세이다.
# prior 고객군의 재주문율
order_products_prior_df.reordered.sum() / order_products_prior_df.shape[0]0.5896974667922161
# train 고객군의 재주문율
order_products_train_df.reordered.sum() / order_products_train_df.shape[0]0.5985944127509629
# prior 고객들 중 재주문한 경험이 있을 경우 1, 없을 경우 0 으로 데이터를 정제한다.
grouped_df = order_products_prior_df.groupby('order_id')['reordered'].aggregate('sum').reset_index()
grouped_df['reordered'].ix[grouped_df['reordered'] > 1] = 1
grouped_df.reordered.value_counts() / grouped_df.shape[0]1 0.879151
0 0.120849
해석 ) prior 고객들 중 재주문한 경험이 있는 경우는 약 88% prior 고객들 중 재주문한 경험이 없는 경우는 약 12%
# train 고객들 중 재주문한 경험이 있을 경우 1, 없을 경우 0 으로 데이터를 정제한다.
grouped_df = order_products_train_df.groupby('order_id')['reordered'].aggregate('sum').reset_index()
grouped_df['reordered'].ix[grouped_df['reordered'] > 1] = 1
grouped_df.reordered.value_counts() / grouped_df.shape[0]
1 0.93444
0 0.06556
해석 ) prior 고객들 중 재주문한 경험이 있는 경우는 약 93% prior 고객들 중 재주문한 경험이 없는 경우는 약 7%
# grouped_df 은 구매자별로 add_to_cart_order 에 담았던 제품의 총 개수
grouped_df = order_products_train_df.groupby('order_id')['add_to_cart_order'].aggregate('max').reset_index()
# cnt_srs 는 add_to_cart_order 에 담긴 각각의 값이 나온 개수
cnt_srs = grouped_df['add_to_cart_order'].value_counts()
plt.figure(figsize=(12,8))
sns.barplot(cnt_srs.index, cnt_srs.values, alpha=0.8)
plt.ylabel('발생 건수', fontsize = 12)
plt.xlabel('add_to_cart_order 에 담긴 제품의 개수', fontsize = 12)
plt.xticks(rotation='vertical')
plt.show()
order_products_prior_df.head()order_id product_id add_to_cart_order reordered
| 0 | 2 | 33120 | 1 | 1 |
| 1 | 2 | 28985 | 2 | 1 |
| 2 | 2 | 9327 | 3 | 0 |
| 3 | 2 | 45918 | 4 | 1 |
| 4 | 2 | 30035 | 5 | 0 |
order_products_prior_df.tail()order_id product_id add_to_cart_order reordered
| 32434484 | 3421083 | 39678 | 6 | 1 |
| 32434485 | 3421083 | 11352 | 7 | 0 |
| 32434486 | 3421083 | 4600 | 8 | 0 |
| 32434487 | 3421083 | 24852 | 9 | 1 |
| 32434488 | 3421083 | 5020 | 10 | 1 |
order_products_prior_df = pd.merge(order_products_prior_df, products_df, on= "product_id" , how="left")
order_products_prior_df = pd.merge(order_products_prior_df, aisles_df, on='aisle_id', how='left')
order_products_prior_df = pd.merge(order_products_prior_df, departments_df, on='department_id', how='left')
order_products_prior_df.head()order_id product_id add_to_cart_order reordered product_name aisle_id department_id aisle department
| 0 | 2 | 33120 | 1 | 1 | Organic Egg Whites | 86 | 16 | eggs | dairy eggs |
| 1 | 2 | 28985 | 2 | 1 | Michigan Organic Kale | 83 | 4 | fresh vegetables | produce |
| 2 | 2 | 9327 | 3 | 0 | Garlic Powder | 104 | 13 | spices seasonings | pantry |
| 3 | 2 | 45918 | 4 | 1 | Coconut Butter | 19 | 13 | oils vinegars | pantry |
| 4 | 2 | 30035 | 5 | 0 | Natural Sweetener | 17 | 13 | baking ingredients | pantry |
- 판매개수 높은 제품 확인
cnt_srs = order_products_prior_df['product_name'].value_counts().sort_values(ascending=False).reset_index().head(20)
cnt_srs.columns = ['제품 이름','판매 갯수']
cnt_srs
# organic 제품이 대다수의 상위권을 차지한 것을 알 수 있다제품 이름 판매 갯수
| 0 | Banana | 472565 |
| 1 | Bag of Organic Bananas | 379450 |
| 2 | Organic Strawberries | 264683 |
| 3 | Organic Baby Spinach | 241921 |
| 4 | Organic Hass Avocado | 213584 |
| 5 | Organic Avocado | 176815 |
| 6 | Large Lemon | 152657 |
| 7 | Strawberries | 142951 |
| 8 | Limes | 140627 |
| 9 | Organic Whole Milk | 137905 |
| 10 | Organic Raspberries | 137057 |
| 11 | Organic Yellow Onion | 113426 |
| 12 | Organic Garlic | 109778 |
| 13 | Organic Zucchini | 104823 |
| 14 | Organic Blueberries | 100060 |
| 15 | Cucumber Kirby | 97315 |
| 16 | Organic Fuji Apple | 89632 |
| 17 | Organic Lemon | 87746 |
| 18 | Apple Honeycrisp Organic | 85020 |
| 19 | Organic Grape Tomatoes | 84255 |
- 제품의 각 상세 카테고리별 판매량
cnt_srs = order_products_prior_df['aisle'].value_counts().head(20)
plt.figure(figsize=(12,8))
sns.barplot(cnt_srs.index, cnt_srs)
plt.xlabel('제품 상세 카테고리' , fontsize= 15)
plt.ylabel('구매량', fontsize= 15)
plt.xticks(fontsize = 15, rotation='vertical')
plt.show()
plt.figure(figsize=(10,10))
temp_series = order_products_prior_df['department'].value_counts()
labels = np.array(temp_series.index)
sizes = np.array((temp_series / temp_series.sum())* 100)
plt.pie(sizes, labels=labels, autopct='%1.1f%%' , startangle= 200)
plt.title('제품 카테고리 분포', fontsize= 15)
plt.show()
# produce(29.2%) 제품군 > dairy eggs(16.7%) > snacks(8.9%) > beverages(8.3%)제품군이 가장 많이 판매됬음을 알 수 있다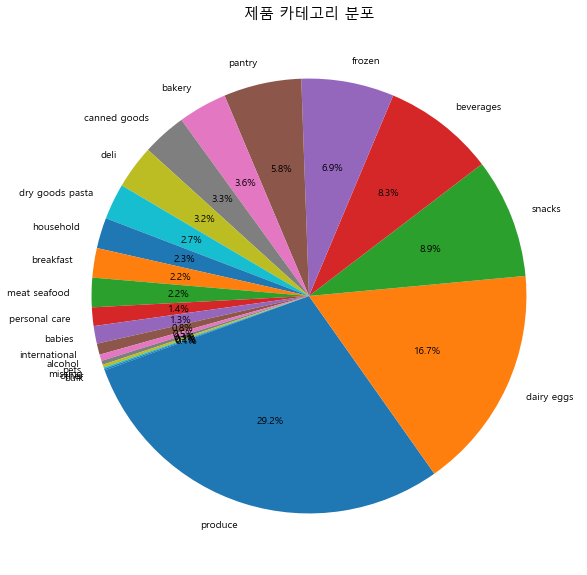
- 제품 카테고리 별 재주문 현황
grouped_df = order_products_prior_df.groupby(['department'])['reordered'].aggregate('mean').reset_index()
plt.figure(figsize=(12,8))
sns.pointplot(grouped_df['department'].values,grouped_df['reordered'].values, alpha = 0.8 , color= color[2])
plt.xlabel('제품 카테고리', fontsize = 18)
plt.ylabel('재주문율' , fontsize= 18)
plt.xticks(rotation = 'vertical', fontsize = 15)
plt.yticks(fontsize = 15)
plt.title('제품 카테고리의 재주문율 ')
plt.show()
# dairy eggs 제품군의 재주문율이 가장 높다 personal care 제품군의 재주문율이 가장 낮다.
grouped_df = order_products_prior_df.groupby(['department_id', 'aisle'])['reordered'].aggregate('mean').reset_index()
fig, ax = plt.subplots(figsize=(15,20))
ax.scatter(grouped_df.reordered.values, grouped_df.department_id.values)
for i, txt in enumerate(grouped_df.aisle.values):
ax.annotate(txt, (grouped_df.reordered.values[i],grouped_df.department_id.values[i]), rotation=45 , ha='center',va='center', color='green')
plt.xlabel('재주문율',fontsize = 20)
plt.ylabel('제품 카테고리 id',fontsize = 20)
plt.title('다른 제품 카테고리의 재주문율' , fontsize =20)
plt.show()
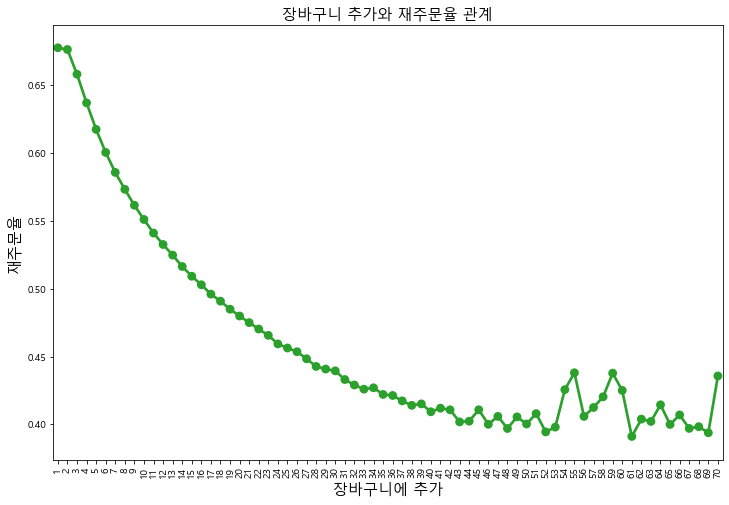
- 장바구니에 추가와 재주문율의 상관관계에 대해 알아보기
order_products_prior_df['add_to_cart_order_mod'] = order_products_prior_df['add_to_cart_order'].copy()
order_products_prior_df['add_to_cart_order_mod'].ix[order_products_prior_df['add_to_cart_order_mod'] > 70] = 70
grouped_df = order_products_prior_df.groupby(['add_to_cart_order_mod'])['reordered'].aggregate('mean').reset_index()
plt.figure(figsize=(12,8))
sns.pointplot(grouped_df['add_to_cart_order_mod'].values, grouped_df['reordered'].values, alpha=0.8, color=color[2])
plt.xlabel('장바구니에 추가' , fontsize = 15)
plt.ylabel('재주문율', fontsize= 15)
plt.title('장바구니 추가와 재주문율 관계', fontsize=15)
plt.xticks(rotation= 'vertical')
plt.show()
# 제일 처음 장바구니에 추가된 제품이 나중에 추가된 제품에 비해 다시 주문될 가능성이 높다.
#이를 통해, 소비자들이 자주 사용하는 제품 먼저 주문 후 새로운 제품을 찾는 경향을 가지고 있음을 알 수 있다.
- 요일별 재주문 추이
order_products_train_df = pd.merge(order_products_train_df,orders_df,on='order_id',how='left')
grouped_df = order_products_train_df.groupby(['order_dow'])['reordered'].aggregate('mean').reset_index()
plt.figure(figsize=(12,8))
sns.barplot(grouped_df['order_dow'].values, grouped_df['reordered'].values,alpha=0.8, color = color[3])
plt.xlabel('요일', fontsize = 15)
plt.ylabel('재주문율',fontsize =15)
plt.xticks(rotation='vertical')
plt.ylim(0.5,0.7)
plt.show()
- 일일 시간대별 재주문율 추이
grouped_df= order_products_train_df.groupby('order_hour_of_day')['reordered'].aggregate('mean').reset_index()
plt.figure(figsize=(12,8))
sns.barplot(grouped_df['order_hour_of_day'].values, grouped_df['reordered'].values, alpha=0.8,color=color[4])
plt.xlabel('하루 중 시간', fontsize =15)
plt.ylabel('재주문율', fontsize =15)
plt.title('일별 재주문율', fontsize = 15)
plt.ylim(0.5,0.7)
plt.show()
- 요일별/ 일일 시간대별 재주문율 현황확인
order_products_train_dforder_id product_id add_to_cart_order reordered user_id eval_set order_number order_dow order_hour_of_day days_since_prior_order
| 0 | 1 | 49302 | 1 | 1 | 112108 | train | 4 | 4 | 10 | 9.0 |
| 1 | 1 | 11109 | 2 | 1 | 112108 | train | 4 | 4 | 10 | 9.0 |
| 2 | 1 | 10246 | 3 | 0 | 112108 | train | 4 | 4 | 10 | 9.0 |
| 3 | 1 | 49683 | 4 | 0 | 112108 | train | 4 | 4 | 10 | 9.0 |
| 4 | 1 | 43633 | 5 | 1 | 112108 | train | 4 | 4 | 10 | 9.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1384612 | 3421063 | 14233 | 3 | 1 | 169679 | train | 30 | 0 | 10 | 4.0 |
| 1384613 | 3421063 | 35548 | 4 | 1 | 169679 | train | 30 | 0 | 10 | 4.0 |
| 1384614 | 3421070 | 35951 | 1 | 1 | 139822 | train | 15 | 6 | 10 | 8.0 |
| 1384615 | 3421070 | 16953 | 2 | 1 | 139822 | train | 15 | 6 | 10 | 8.0 |
| 1384616 | 3421070 | 4724 | 3 | 1 | 139822 | train | 15 | 6 | 10 | 8.0 |
grouped_df = order_products_train_df.groupby(['order_dow', 'order_hour_of_day'])['reordered'].aggregate('mean').reset_index()
grouped_df = grouped_df.pivot(values = 'reordered', columns= 'order_hour_of_day',index='order_dow')plt.figure(figsize=(12,8))
sns.heatmap(grouped_df)
plt.title('요일별 재주문율 vs 일일별 재주문율 ')
plt.xlabel('하루 중 구매시간')
plt.ylabel('요일')
plt.yticks([2,3,4,5,6,0,1],['월','화','수','목','금','토','일'])
plt.show()
# 결과
prior 고객군 insight
- prior 고객군의 최대 구매시간은 토요일 오후 1~3시 와 일요일 10시이다.
train 고객군 insight
- train 고객군의 최대 구매시간은 수요일과 토요일 아침 6~7시간대이다.
- train 고객군은 하루 중 6,7,8시에 재주문율이 가장 높고 9시 ~12시까지 주문율이 감소하는 경향을 보인다.
종합 insight
- 시간별 판매량 : 아침 9시에 판매량이 가장 높고, 새벽 3시에 판매량이 가장 낮다.아침 9시~ 17시까지이 판매량의 70% 를 차지한다.
- 요일별 판매량 : 판매량이 가장 높은 요일은 30일, 낮은 요일은 25일 이다. 1일~7일까지는 증가추세이고, 8일~29일까지는 감소추세이다.
- 제품군에 따른 주문율 :produce(29.2%) 제품군 > dairy eggs(16.7%) > snacks(8.9%) > beverages(8.3%)제품군이 가장 많이 판매됬음을 알 수 있다
- 상세 제품군에 따른 주문율 : organic 제품이 대다수의 판매 상위권을 차지한 것을 알 수 있다
- 상세 제품군에 따른 재주문율 : dairy eggs 제품군의 재주문율이 가장 높다 personal care 제품군의 재주문율이 가장 낮다.
- 장바구니와 관련된 구매성향 : 제일 처음 장바구니에 추가된 제품이 나중에 추가된 제품에 비해 다시 주문될 가능성이 높다. 이를 통해, 소비자들이 자주 사용하는 제품 먼저 주문 후 새로운 제품을 찾는 경향을 가지고 있음을 알 수 있다.
# 필사 참고 URL
https://www.kaggle.com/sudalairajkumar/simple-exploration-notebook-instacart
Simple Exploration Notebook - Instacart
Explore and run machine learning code with Kaggle Notebooks | Using data from Instacart Market Basket Analysis
www.kaggle.com
'Kaggle' 카테고리의 다른 글
| [ Kaggle ] 초간단 Kaggle 에서 API로 데이터셋 다운받기 (0) | 2020.03.30 |
|---|